# Create random input and output data # 创建随机输入输出数据 x = np.linspace(-math.pi, math.pi, 2000) y = np.sin(x)
# Randomly initialize weights # 随机初始化权重 有四个权重 a = np.random.randn() b = np.random.randn() c = np.random.randn() d = np.random.randn()
learning_rate = 1e-6#学习率 for t inrange(2000): # Forward pass: compute predicted y # 前向传播:计算y的值 # y = a + b x + c x^2 + d x^3 # 我在这里把它理解成泰勒展开式,展开的越多的话应该越精确 y_pred = a + b * x + c * x ** 2 + d * x ** 3
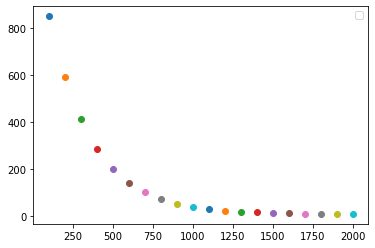
# Compute and print loss # 计算并且输出损失 y(预测)-y(实际)之差的平方 loss = np.square(y_pred - y).sum() if t % 100 == 99: print(t, loss)
# Backprop to compute gradients of a, b, c, d with respect to loss # 反向传播计算a,b,c,d相对于损失的梯度 grad_y_pred = 2.0 * (y_pred - y) grad_a = grad_y_pred.sum() grad_b = (grad_y_pred * x).sum() grad_c = (grad_y_pred * x ** 2).sum() grad_d = (grad_y_pred * x ** 3).sum()
# Update weights # 更新权重 a -= learning_rate * grad_a b -= learning_rate * grad_b c -= learning_rate * grad_c d -= learning_rate * grad_d
print(f'Result: y = {a} + {b} x + {c} x^2 + {d} x^3') #得出sinx的三阶多项式
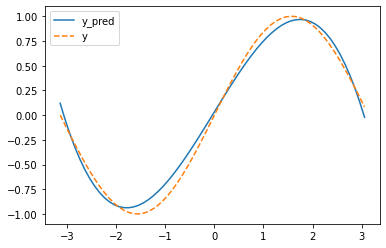
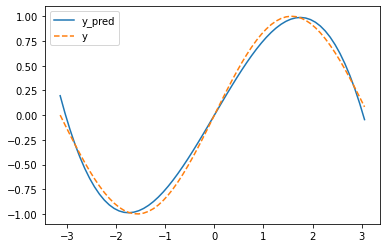
接下来绘制函数,查看差别
1 2 3 4 5 6 7
i = np.arange(-math.pi, math.pi, 0.1) j = a + b * i + c * i ** 2 + d * i ** 3 k = np.sin(i) plt.plot(i,j,label = "y_pred") plt.plot(i,k,label = 'y',linestyle = '--') plt.legend() plt.show()
dtype = torch.float # device = torch.device("cpu") device = torch.device("cuda:0") # Uncomment this to run on GPU
# Create random input and output data x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype) y = torch.sin(x)
# Randomly initialize weights a = torch.randn((), device=device, dtype=dtype) b = torch.randn((), device=device, dtype=dtype) c = torch.randn((), device=device, dtype=dtype) d = torch.randn((), device=device, dtype=dtype)
learning_rate = 1e-6 for t inrange(100000): # Forward pass: compute predicted y y_pred = a + b * x + c * x ** 2 + d * x ** 3
# Compute and print loss loss = (y_pred - y).pow(2).sum().item() if t % 100 == 99: print(t, loss)
# Backprop to compute gradients of a, b, c, d with respect to loss grad_y_pred = 2.0 * (y_pred - y) grad_a = grad_y_pred.sum() grad_b = (grad_y_pred * x).sum() grad_c = (grad_y_pred * x ** 2).sum() grad_d = (grad_y_pred * x ** 3).sum()
# Update weights using gradient descent a -= learning_rate * grad_a b -= learning_rate * grad_b c -= learning_rate * grad_c d -= learning_rate * grad_d
print(f'Result: y = {a.item()} + {b.item()} x + {c.item()} x^2 + {d.item()} x^3')
out[i][j][k] = input[index[i][j][k]][j][k] # if dim == 0 out[i][j][k] = input[i][index[i][j][k]][k] # if dim == 1 out[i][j][k] = input[i][j][index[i][j][k]] # if dim == 2
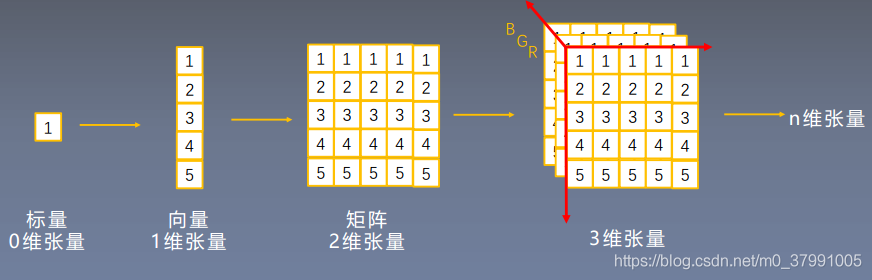
torch.squeeze(input, dim, out=None) #默认移除所有size为1的维度,当dim指定时,移除指定size为1的维度. 返回的tensor会和input共享存储空间,所以任何一个的改变都会影响另一个 torch.unsqueeze(input, dim, out=None) #扩展input的size, 如 A x B 变为 1 x A x B
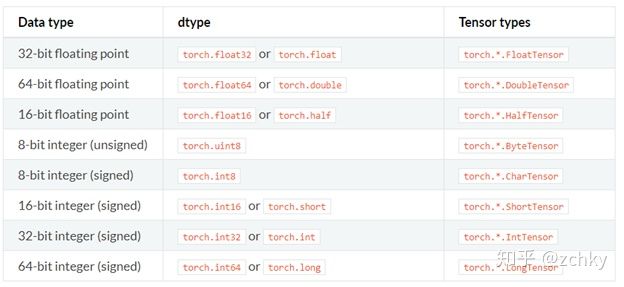
torch.set_default_tensor_type() # 同上,对torch.tensor()设置默认的tensor类型 >>> torch.tensor([1.2, 3]).dtype # initial default for floating point is torch.float32 torch.float32 >>> torch.set_default_dtype(torch.float64) >>> torch.tensor([1.2, 3]).dtype # a new floating point tensor torch.float64 >>> torch.set_default_tensor_type(torch.DoubleTensor) >>> torch.tensor([1.2, 3]).dtype # a new floating point tensor torch.float64
dtype = torch.float device = torch.device("cpu") # device = torch.device("cuda:0") # Uncomment this to run on GPU
# Create Tensors to hold input and outputs. 创建张量来保存输入和输出。 # By default, requires_grad=False, which indicates that we do not need to # compute gradients with respect to these Tensors during the backward pass. # 默认情况下,requires_grad=False,这表示我们不需要在向后传递期间计算关于这些张量的梯度。 x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype) y = torch.sin(x)
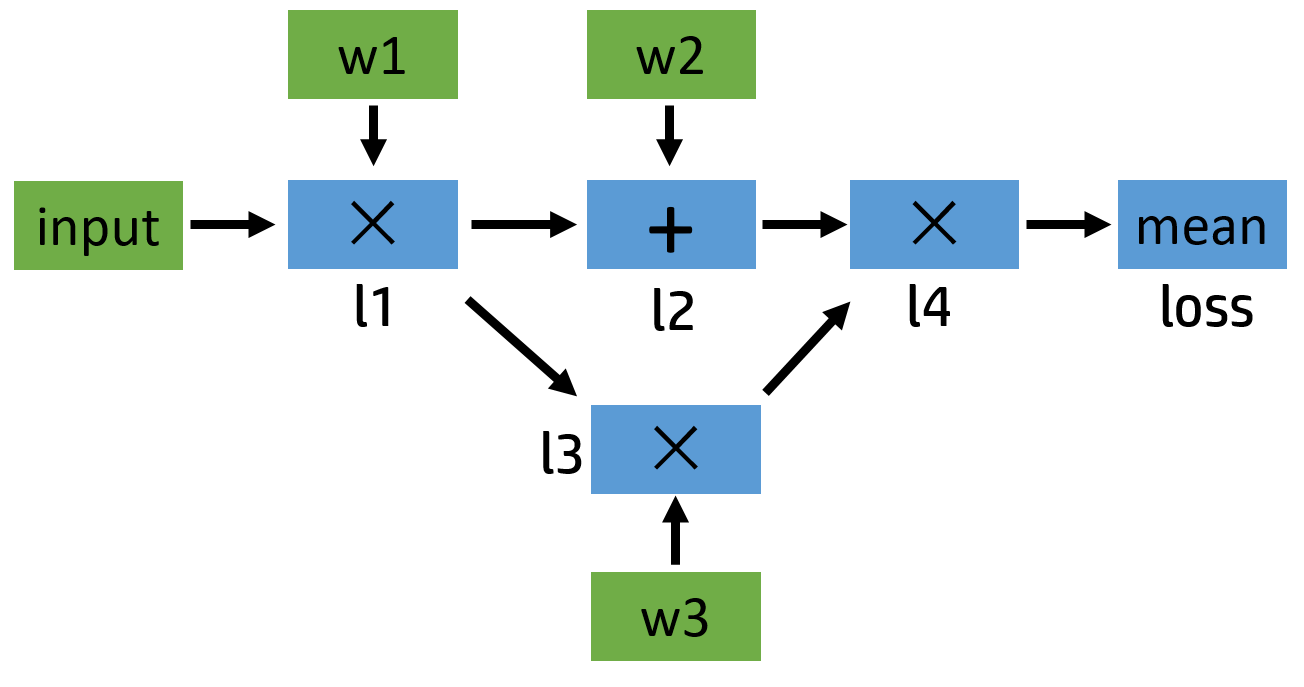
# Create random Tensors for weights. For a third order polynomial, we need # 4 weights: y = a + b x + c x^2 + d x^3 # 为权重创建随机张量。对于三阶多项式,我们需要4个权值:y=a+bx+cx^2+dx^3 # Setting requires_grad=True indicates that we want to compute gradients with # respect to these Tensors during the backward pass. # 设置requires_grad=True表示我们希望在向后传递期间计算相对于这些张量的梯度。 a = torch.randn((), device=device, dtype=dtype, requires_grad=True) b = torch.randn((), device=device, dtype=dtype, requires_grad=True) c = torch.randn((), device=device, dtype=dtype, requires_grad=True) d = torch.randn((), device=device, dtype=dtype, requires_grad=True)
learning_rate = 1e-6 for t inrange(2000): # Forward pass: compute predicted y using operations on Tensors. 前向传递:使用张量运算计算预测的y。 y_pred = a + b * x + c * x ** 2 + d * x ** 3
# Compute and print loss using operations on Tensors. 使用张量运算计算并打印损耗。 # Now loss is a Tensor of shape (1,) 现在损失是一个形状的张量(1,) # loss.item() gets the scalar value held in the loss. loss.item()获取丢失中保存的标量值。 loss = (y_pred - y).pow(2).sum() if t % 100 == 99: print(t, loss.item())
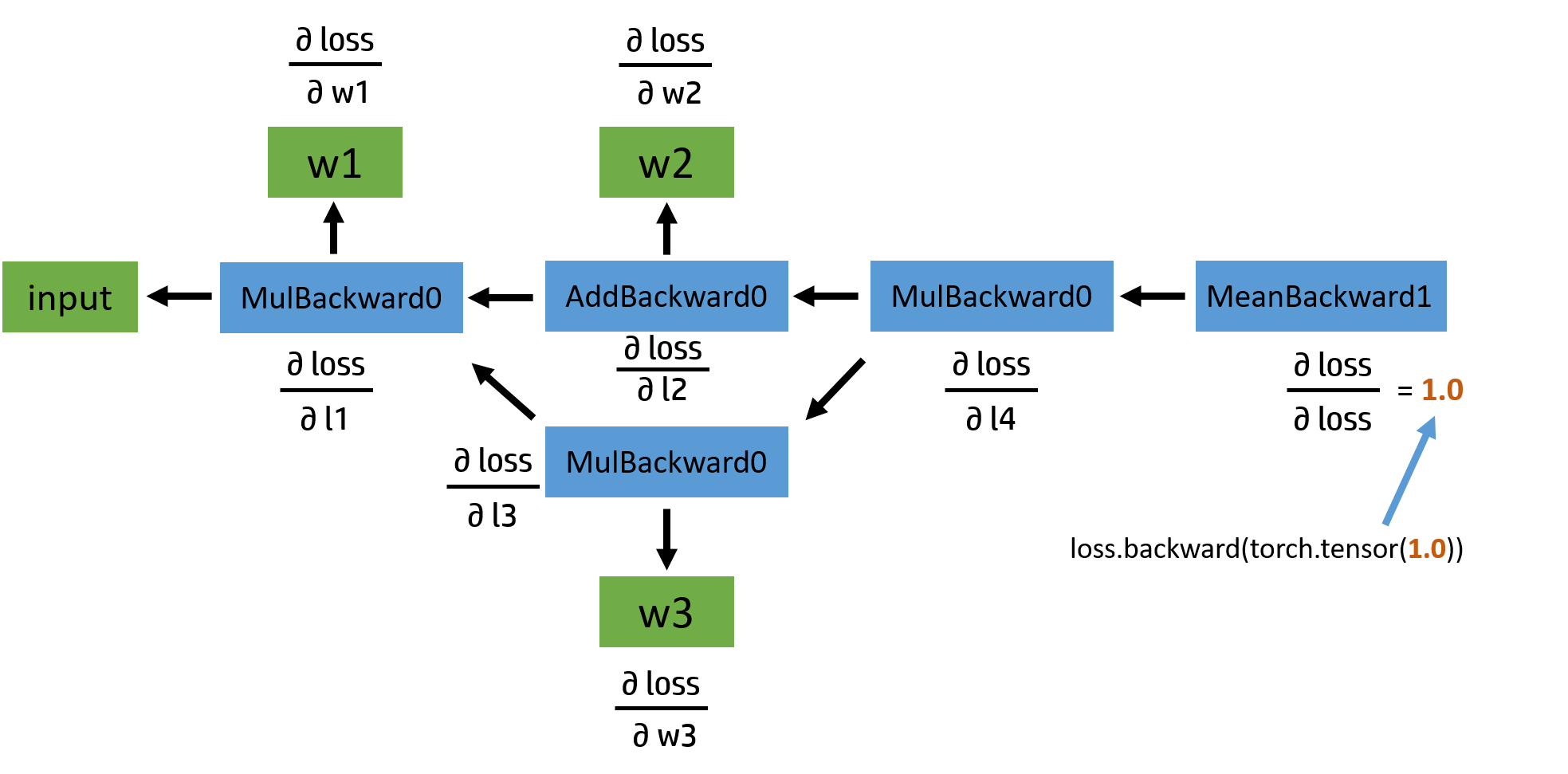
# Use autograd to compute the backward pass. This call will compute the # gradient of loss with respect to all Tensors with requires_grad=True. # 使用autograd计算向后传球。此调用将计算与所有张量相关的损失梯度,且requires_grad=True。 # After this call a.grad, b.grad. c.grad and d.grad will be Tensors holding # the gradient of the loss with respect to a, b, c, d respectively. # 在这之后调用a.grad,b.grad c.grad和d.grad将分别是关于a,b,c,d保持损失梯度的张量。 loss.backward()
# Manually update weights using gradient descent. Wrap in torch.no_grad() # because weights have requires_grad=True, but we don't need to track this # in autograd. # 使用梯度下降手动更新权重。包裹火炬号()因为权重要求_grad=True,但我们不需要在autograd中跟踪它。 with torch.no_grad(): a -= learning_rate * a.grad b -= learning_rate * b.grad c -= learning_rate * c.grad d -= learning_rate * d.grad print(a.grad) # Manually zero the gradients after updating weights 更新权重后手动将渐变归零 a.grad = None b.grad = None c.grad = None d.grad = None
print(f'Result: y = {a.item()} + {b.item()} x + {c.item()} x^2 + {d.item()} x^3')
loss.backward() # RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation ...
每次 tensor 在进行 inplace 操作时,变量 _version 就会加1,其初始值为0。在正向传播过程中,求导系统记录的 b 的 version 是0,但是在进行反向传播的过程中,求导系统发现 b 的 version 变成1了,所以就会报错了。但是还有一种特殊情况不会报错,就是反向传播求导的时候如果没用到 b 的值(比如 y=x+1, y 关于 x 的导数是1,和 x 无关),自然就不会去对比 b 前后的 version 了,所以不会报错。
loss = (a*a).mean() loss.backward() # RuntimeError: leaf variable has been moved into the graph interior
我们看到,在进行对 a 的重新 inplace 赋值之后,表示了 a 是通过 copy operation 生成的,grad_fn 都有了,所以自然而然不是叶子节点了。本来是该有导数值保留的变量,现在成了导数会被自动释放的中间变量了,所以 PyTorch 就给你报错了。还有另外一种情况:
1 2 3
a = torch.tensor([10., 5., 2., 3.], requires_grad=True) a.add_(10.) # 或者 a += 10. # RuntimeError: a leaf Variable that requires grad has been used in an in-place operation.
classLegendrePolynomial3(torch.autograd.Function): """ We can implement our own custom autograd Functions by subclassing torch.autograd.Function and implementing the forward and backward passes which operate on Tensors. 我们可以通过子类化实现我们自己的自定义autograd函数torch.autograd.功能实现对张量进行操作的向前和向后传球。 """
@staticmethod defforward(ctx, input): """ In the forward pass we receive a Tensor containing the input and return a Tensor containing the output. ctx is a context object that can be used to stash information for backward computation. You can cache arbitrary objects for use in the backward pass using the ctx.save_for_backward method. 在向前传递中,我们接收包含输入的张量,并返回包含输出的张量。 ctx是一个上下文对象,可以用来为向后计算存储信息。可以使用ctx.save_for_backward方法。 """ ctx.save_for_backward(input) return0.5 * (5 * input ** 3 - 3 * input)
@staticmethod defbackward(ctx, grad_output): """ In the backward pass we receive a Tensor containing the gradient of the loss with respect to the output, and we need to compute the gradient of the loss with respect to the input. 在后向过程中,我们接收到一个张量,其中包含了与输出有关的损耗梯度,并且我们需要计算与输入有关的损耗梯度。 """ input, = ctx.saved_tensors return grad_output * 1.5 * (5 * input ** 2 - 1)
dtype = torch.float device = torch.device("cpu") # device = torch.device("cuda:0") # Uncomment this to run on GPU
# Create Tensors to hold input and outputs. # By default, requires_grad=False, which indicates that we do not need to # compute gradients with respect to these Tensors during the backward pass. x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype) y = torch.sin(x)
# Create random Tensors for weights. For this example, we need # 4 weights: y = a + b * P3(c + d * x), these weights need to be initialized # not too far from the correct result to ensure convergence. # 为权重创建随机张量。对于这个例子,我们需要4个权值:y=a+b*P3(c+d*x),这些权值需要在离正确结果不太远的地方初始化以确保收敛。 # Setting requires_grad=True indicates that we want to compute gradients with # respect to these Tensors during the backward pass. # 设置requires_grad=True表示我们希望在向后传递期间计算相对于这些张量的梯度。 a = torch.full((), 0.0, device=device, dtype=dtype, requires_grad=True) b = torch.full((), -1.0, device=device, dtype=dtype, requires_grad=True) c = torch.full((), 0.0, device=device, dtype=dtype, requires_grad=True) d = torch.full((), 0.3, device=device, dtype=dtype, requires_grad=True)
learning_rate = 5e-6 for t inrange(2000): # To apply our Function, we use Function.apply method. We alias this as 'P3'. P3 = LegendrePolynomial3.apply
# Forward pass: compute predicted y using operations; we compute # P3 using our custom autograd operation. y_pred = a + b * P3(c + d * x)
# Compute and print loss loss = (y_pred - y).pow(2).sum() if t % 100 == 99: print(t, loss.item())
# Use autograd to compute the backward pass. loss.backward()
# Update weights using gradient descent with torch.no_grad(): a -= learning_rate * a.grad b -= learning_rate * b.grad c -= learning_rate * c.grad d -= learning_rate * d.grad
# Manually zero the gradients after updating weights a.grad = None b.grad = None c.grad = None d.grad = None