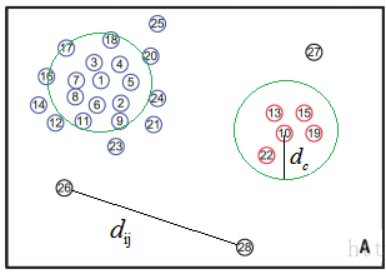
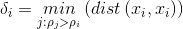密度峰值算法(Clustering by fast search and find of density peaks)由Alex Rodriguez和Alessandro Laio于2014年提出,并将论文发表在Science上。Science上的这篇文章《Clustering by fast search and find of density peaks》主要讲的是一种基于密度的聚类方法,基于密度的聚类方法的主要思想是寻找被低密度区域分离的高密度区域。 密度峰值算法(DPCA)基于这样的假设:(1)类簇中心点的密度大于周围邻居点的密度;(2)类簇中心点与更高密度点之间的距离相对较大。因此,DPCA主要有两个需要计算的量:第一,局部密度;第二,与高密度点之间的距离。
# 计算各点到聚类中心的距离(dist) defget_each_dis(distance_all, point_density): nn = [] for i inrange(len(point_density)): aa = [] for j inrange(len(point_density)): if point_density[i] < point_density[j]: aa.append(j) ll = get_min_dis(aa, i, distance_all, point_density) nn.append(ll) return nn
# 归类,判断所有点与V中点的距离,距离最近的划为一类,输出每个数据的类别 defclassify(distance_all, v): c = np.random.rand(distance_all.shape[0]) for i inrange(distance_all.shape[0]): dist = [] for j inrange(len(v)): dist.append(distance_all[i][int(v[j])]) c[i] = dist.index(min(dist)) + 1 return c
import matplotlib.pyplot as plt import numpy as np
feature_num = 4# 根据特征分成四组
# 读取文件将数据存到一个列表 defread_file(file_name): file = open(file_name, 'r') array = [] for line in file: array.append([int(x) for x in line.split()]) # int将字符串转换成整型,方便后续计算 file.close() return array
# 将距离矩阵归一化 可以直接遍历除以行最大值,我这里的方法有点画蛇添足 defnorm(data): data = np.array(data).astype(float) max_array = np.zeros(data.shape[1]) for i inrange(data.shape[0]): for j inrange(data.shape[1]): ifabs(data[i][j]) > max_array[j]: max_array[j] = abs(data[i][j]) for i inrange(data.shape[0]): for j inrange(data.shape[1]): data[i][j] = data[i][j] / max_array[j] return data
for i inrange(len(data)): for n inrange(len(data)): distance_all[i][n] = np.sqrt(np.square(abs(data[i][0]) - abs(data[n][0])) + np.square(abs(data[i][1]) - abs(data[n][1])) + np.square(data[i][2] - data[n][2])) # np.square(data[i][3]-data[n][3])+ # np.square(data[i][4]-data[n][4])+ # np.square(data[i][5]-data[n][5])+ # np.square(data[i][6]-data[n][6])+ # np.square(data[i][7]-data[n][7])) # print('距离矩阵:\n', distance_all, '\n') return distance_all
defcal_den(distance_all, min_distance): point_density = np.random.rand(distance_all.shape[0]) for i inrange(distance_all.shape[0]): tmp = 0 for n inrange(distance_all.shape[0]): if0 < distance_all[i][n] < min_distance: tmp = tmp + 1 point_density[i] = tmp # print('点密度数组:\n', point_density, '\n')
return point_density
# 计算密度最大的点的聚类中心距离 defget_max_dis(distance_all, point_density): point_density = point_density.tolist() a = max(point_density) # 寻找密度最大的点 b = point_density.index(a) # 寻找密度最大的索引 c = max(distance_all[b]) # 密度最大点的最大中心距离
return c
# 到点密度大于自身最近点的距离 defget_min_dis(point, i, distance_all, point_density): min_distance = [] if point: for j in point: min_distance.append(distance_all[i][j]) returnmin(min_distance) else: max_distance = get_max_dis(distance_all, point_density) return max_distance
# 计算各点到聚类中心的距离(dist) defget_each_dis(distance_all, point_density): nn = [] for i inrange(len(point_density)): aa = [] for j inrange(len(point_density)): if point_density[i] < point_density[j]: aa.append(j) ll = get_min_dis(aa, i, distance_all, point_density) nn.append(ll) return nn
# 分簇,根据需要划分的特征结果数找到数据密度中最大的n个点 defclustering(point_density, delta): mul1 = (point_density * delta).tolist() mul2 = mul1.copy() mul2.sort(reverse=True) v = np.random.rand(feature_num) for i inrange(feature_num): for j inrange(len(mul1)): if mul1[j] == mul2[i]: v[i] = mul1.index(mul1[j]) return v
# 归类,判断所有点与V中点的距离,距离最近的划为一类,输出每个数据的类别 defclassify(distance_all, v): c = np.random.rand(distance_all.shape[0]) for i inrange(distance_all.shape[0]): dist = [] for j inrange(len(v)): dist.append(distance_all[i][int(v[j])]) c[i] = dist.index(min(dist)) + 1 return c
# 计算最大最小距离 defmax_min_dis(distance_all): max_dis = 0 min_dis = 999 for i inrange(distance_all.shape[0]): for j inrange(distance_all.shape[0]): if distance_all[i][j] == 0: continue if distance_all[i][j] > max_dis: max_dis = distance_all[i][j] if distance_all[i][j] < min_dis: min_dis = distance_all[i][j] return max_dis, min_dis
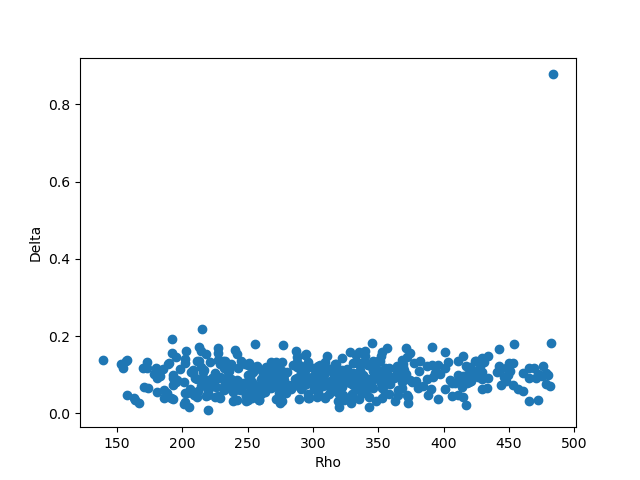
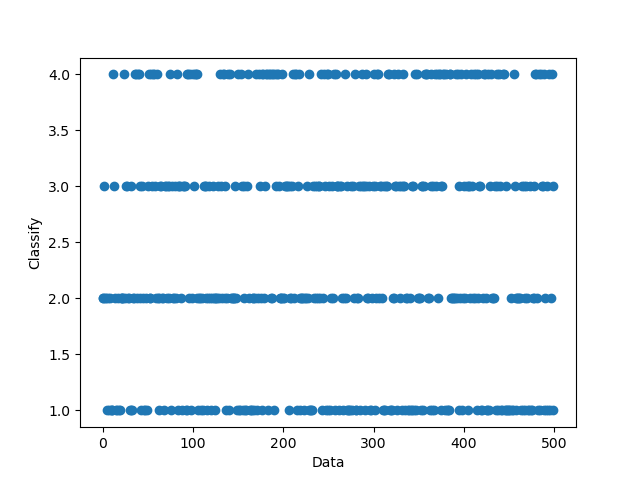
defmain(): array = read_file('data.txt') array = norm(array) distance_all = cal_dis(array) max_dis, min_dis = max_min_dis(distance_all) point_density = cal_den(distance_all, 0.5 * (max_dis + min_dis)) nn = get_each_dis(distance_all, point_density) v = clustering(point_density, nn) c = classify(distance_all, v) print(c) x = [] y = [] z = [] for i inrange(len(array)): x.append(array[i][0]) y.append(array[i][1]) z.append(array[i][2]) fig = plt.figure(0) ax = fig.add_subplot(111, projection='3d') ax.scatter(x, y) plt.figure(1) plt.scatter(point_density.tolist(), nn) plt.figure(2) plt.scatter(range(0, 500), c.tolist()) plt.show()
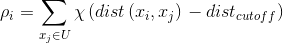
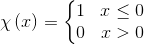 ,这个公式的含义是说找到与第
,这个公式的含义是说找到与第