本章小结
决策树分类器就像带有终止块的流程图,终止块表示分类结果。开始处理数据集时,我们首先需要测量集合中数据的不一致性,也就是熵,然后寻找最优方案划分数据集,直到数据集中的所有数据属于同一分类。ID3算法可以用于划分标称型数据集。构建决策树时,我们通常采用递归的方法将数据集转化为决策树。一般我们并不构造新的数据结构,而是使用Python语言内嵌的数据结构字典存储树节点信息。
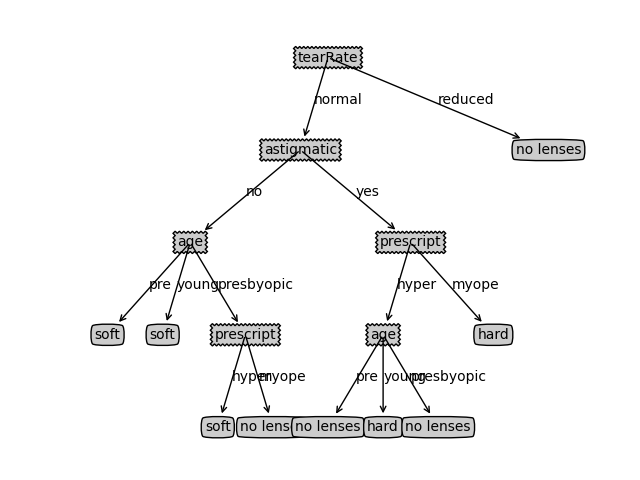
使用Matplotlib的注解功能,我们可以将存储的树结构转化为容易理解的图形。Python语言的pickle模块可用于存储决策树的结构。隐形眼镜的例子表明决策树可能会产生过多的数据集划分,从而产生过度匹配数据集的问题。我们可以通过裁剪决策树,和冰箱零的无法产生大量信息增益的叶节点,消除过度匹配问题。
还有其他的决策树的构造算法,最流行的是C4.5和CART,第9章讨论回归问题是将介绍CART算法。
想要学好决策树算法,首先需要了解信息熵,感觉这个概念既抽象也不抽象,按照例子来分析好像有点眉目,但是再看又不懂了,之前看西瓜书就一知半解的,感觉很复杂,只有靠多看资料才能多了解。
借助知乎回答
信息熵:
信息熵的公式
先抛出信息熵公式如下:
$$
H(X)=-\sum_{i=1}^{n}{p(x_i)\log p(x_i)}
$$
其中$P(x_i)$代表随机事件X为$x_i$的概率,下面来逐步介绍信息熵的公式来源!
信息量
信息量是对信息的度量,就跟时间的度量是秒一样,当我们考虑一个离散的随机变量x的时候,当我们观察到的这个变量的一个具体值的时候,我们接收到了多少信息呢?
多少信息用信息量来衡量,我们接受到的信息量跟具体发生的事件有关。
信息的大小跟随机事件的概率有关。越小概率的事情发生了产生的信息量越大,如湖南产生的地震了;越大概率的事情发生了产生的信息量越小,如太阳从东边升起来了(肯定发生嘛,没什么信息量)。
例子
一个具体事件的信息量应该是随着其发生概率而递减的,且不能为负。
但是这个表示信息量函数的形式怎么找呢?
随着概率增大而减少的函数形式太多了!不要着急,我们还有下面这条性质
如果我们有俩个不相关的事件x和y,那么我们观察到的俩个事件同时发生时获得的信息应该等于观察到的事件各自发生时获得的信息之和,即:
h(x,y) = h(x) + h(y)
由于x,y是俩个不相关的事件,那么满足p(x,y) = p(x)*p(y).
根据上面推导,我们很容易看出h(x)一定与p(x)的对数有关(因为只有对数形式的真数相乘之后,能够对应对数的相加形式,可以试试)。因此我们有信息量公式如下:
$h(x)=-\log_2 p(x)$
下面解决俩个疑问?
(1)为什么有一个负号
信息量取概率的负对数,其实是因为信息量的定义是概率的倒数的对数。而用概率的倒数,是为了使概率越大,信息量越小,同时因为概率的倒数大于1,其对数自然大于0了。
为什么底数为2
这是因为,我们只需要信息量满足低概率事件x对应于高的信息量。那么对数的选择是任意的。我们只是遵循信息论的普遍传统,使用2作为对数的底!
信息熵
下面我们正式引出信息熵。
信息量度量的是一个具体事件发生了所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。即
$$
H(X)=-sum(p(x)\log_2 p(x))
$$
转换一下为:
$$
H(X)=-\sum_{i=1}^{n}{p(x_i)\log p(x_i)}
$$
最终我们的公式来源推导完成了。
这里我再说一个对信息熵的理解。信息熵还可以作为一个系统复杂程度的度量,如果系统越复杂,出现不同情况的种类越多,那么他的信息熵是比较大的。
如果一个系统越简单,出现情况种类很少(极端情况为1种情况,那么对应概率为1,那么对应的信息熵为0),此时的信息熵较小。
三种不同的决策树
- ID3:取值多的属性,更容易使数据更纯,其信息增益更大。
训练得到的是一棵庞大且深度浅的树:不合理。 - C4.5:采用信息增益率替代信息增益。
- CART:以基尼系数替代熵,最小化不纯度,而不是最大化信息增益。
参考资料
机器学习—决策树模型 ID3/C4.5/CART三种算法的区别
勘误
P36 Python命令提示符下输入下列命令
1 | reload(trees.py) |
错误与之前错误类似,后不再解释。详情查看前一章。
P44 绘制图3-5
这里不是错误,是一个提示,就是图片中的汉字无法显示。
1 | D:\Anaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:214: RuntimeWarning: Glyph 20915 missing from cur |
解决方法:
在py文件头部添加一行代码
1 | plt.rcParams['font.sans-serif']=['SimHei'] |
还有一种方法就是在matplotlib字体目录中添加中文字体
第一步:将中文字体复制到matplotlib的字体目录中
中文字体以微软雅黑为例,在 C:\Windows\Fonts 下面找到“微软雅黑”字体。matplotlib默认安装在 %PythonPath%\Lib\site-packages 目录下。
复制微软雅黑字体到 %PythonPath%\Lib\site-packages\matplotlib\mpl-data\fonts\ttf\ 中
第二步:配置文件matplotlibrc
在 %PythonPath%\Lib\site-packages\matplotlib\mpl-data\ 找到matplotlibrc文件,用记事本打开做如下修改并保存。

找到设置font.family的行,改为font.family : monospace,注意去掉前面的#号。
在下面添加一行:font.monospace : Microsoft YaHei
P45 获取叶节点的数目和树的层数
在将myTree转存时出现错误
1 | treePlotter.getNumLeafs(myTree) |
两个函数出现了同样的问题
1 | firstStr = myTree.keys()[0] |
原因是dict的values()和keys()返回的并不是一个真正的数组,所以,处理方法也很简单,只需要用list()强制转换一下即可
1 | firstStr = list(myTree.keys())[0] |
**radiansdict.keys()**返回一个迭代器,可以使用 list() 来转换为列表
radiansdict.values() 返回一个迭代器,可以使用 list() 来转换为列表
所以 firstStr = myTree.keys()[0] 应该是获取不到键的字符串的,不知道有没有更好的办法,知识还是不够啊。
P50 使用pickle模块存储决策树
1 | trees.storeTree(myTree,'classifierStorage.txt') |
python的pickle模块实现了基本的数据序列和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
基本接口:
pickle.dump(obj, file, [,protocol])
注解:将对象obj保存到文件file中去。
protocol为序列化使用的协议版本,0:ASCII协议,所序列化的对象使用可打印的ASCII码表示;1:老式的二进制协议;2:2.3版本引入的新二进制协议,较以前的更高效。其中协议0和1兼容老版本的python。protocol默认值为0。
file:对象保存到的类文件对象。file必须有write()接口, file可以是一个以’w’方式打开的文件或者一个StringIO对象或者其他任何实现write()接口的对象。如果protocol>=1,文件对象需要是二进制模式打开的。
pickle.load(file)
注解:从file中读取一个字符串,并将它重构为原来的python对象。
file:类文件对象,有read()和readline()接口。
由上可知,需要的是二进制文件,所以将两个函数中的打开文件方式修改
1 | fw = open(filename, 'wb') |
pickle的功能就是把你上次计算得到的数据保存起来,当你需要使用这些数据时,直接通过reload把数据恢复了就行,这样的好处有:
1、被pickle的数据,在被多次reload时,不需要重新去计算得到这些数据,这样节省计算机资源,如果你不pickle,你每调用一次数据,就要计算一次。
2、通过pickle的数据,被reload时,可以更好的被内存调用,不需要经过数据格式的转换。
有人可能觉得,我直接通过open把数据写到一个txt文档也能达到以上的效果,但是这样做的结果是,你能够达到pickle的功能,把数据保存起来,但是当你再去调用这些数据时,你的txt格式的数据,没有pickle的数据读取更高效。
另外还有一点,你通过open把数据存储到txt中时的效率,就不如pickle的效率高。
综上,你如果只是做一次的数据存储和调用,以及数据量很小的情况下,你可以用open等方法保存数据和调用数据,但是当你需要通过大量计算得到一个数据,同时后期还会多次使用这个数据时,pickle的节省计算机资源的效果就出来了。
python 中file与pickle的区别
本质区别就是: 存取类型,读取速度(两方面)
pickle可以保存任何数据格式的数据,在经常存取的场景(保存和恢复状态)下读取更加高效
file则是只能读取和存储字符串格式的数据,适用于小场景,读取不那么频繁、数据格式不那么复杂
说下open函数作用:
open函数则是将当前读取的数据/状态存储到内存中,然后方便调用其他函数(file,pickle函数)写入或者读取
