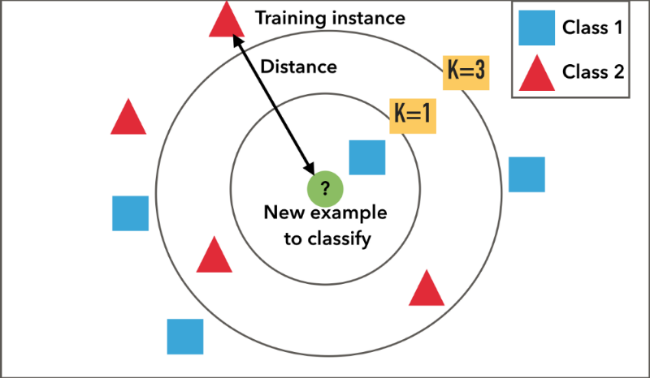
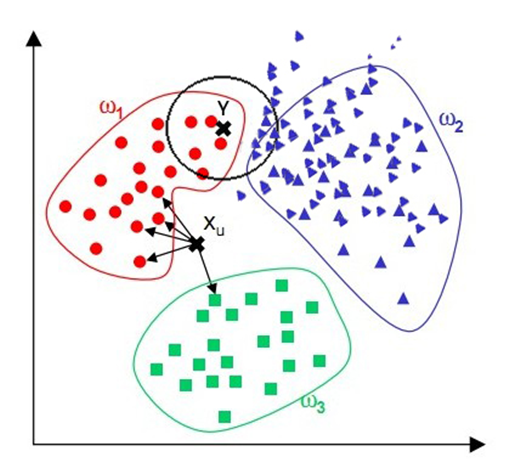
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
| from numpy import *
import operator
from os import listdir
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
returnMat = zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0: 3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat, classLabelVector
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m, 1))
normDataSet = normDataSet / tile(ranges, (m, 1))
return normDataSet, ranges, minVals
def datingClassTest():
hoRatio = 0.10
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m * hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))
if classifierResult != datingLabels[i]:
errorCount += 1.0
print("the total error rate is: %f" % (errorCount / float(numTestVecs)))
def classifyPerson():
resultList = ['not at all', 'in small doses', 'in large doses']
percentTats = float(input("percentage of time spent playing video games?"))
ffMiles = float(input("frequent flier miles earned per year?"))
iceCream = float(input("liters of ice cream consumed per year?"))
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = array([ffMiles, percentTats, iceCream])
classifierResult = classify0((inArr - minVals) / ranges, normMat, datingLabels, 3)
print("You will probably like this person: ", resultList[classifierResult - 1])
def img2vector(filename):
returnVect = zeros((1, 1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0, 32 * i + j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits')
m = len(trainingFileList)
trainingMat = zeros((m, 1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i, :] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print("the classifier came back with:%d, the real answer is : %d" % (classifierResult, classNumStr))
if classifierResult != classNumStr:
errorCount += 1.0
print("\nthe total number of errors is: %d" % errorCount)
print("\nthe total error rate is: %f" % (errorCount / float(mTest)))
|